DeepSeek-R1 | RL-Enhanced Reasoning LLM
DeepSeek-AI has launched its first-generation reasoning models, DeepSeek-R1 and DeepSeek-R1-Zero. By leveraging Reinforcement Learning (RL), cold-start data, and distillation techniques, these models significantly enhance the reasoning capabilities of large language models (LLMs) and have achieved outstanding performance across multiple reasoning benchmarks.
LLMs have made remarkable progress in natural language processing (NLP), excelling in understanding, generation, and reasoning tasks. However, several challenges remain. Developing robust reasoning capabilities often requires extensive supervised fine-tuning, limiting scalability and generalization. Issues like low readability and the trade-off between computational efficiency and reasoning complexity persist.
To address these challenges, DeepSeek-AI has introduced the DeepSeek-R1 model, which integrates RL to enhance reasoning. This work introduces two innovative models:
- DeepSeek-R1-Zero: Trained exclusively using RL, it exhibits emergent reasoning behaviors, such as long Chain-of-Thought (CoT) reasoning.
- DeepSeek-R1: Building on R1-Zero, it incorporates a multi-stage training process to tackle challenges like readability and multilinguality while maintaining high reasoning performance.
These models combine advanced RL techniques with structured training methodologies to overcome existing limitations, offering scalability and usability.
Reinforcement Learning for Reasoning Tasks
DeepSeek-R1-Zero
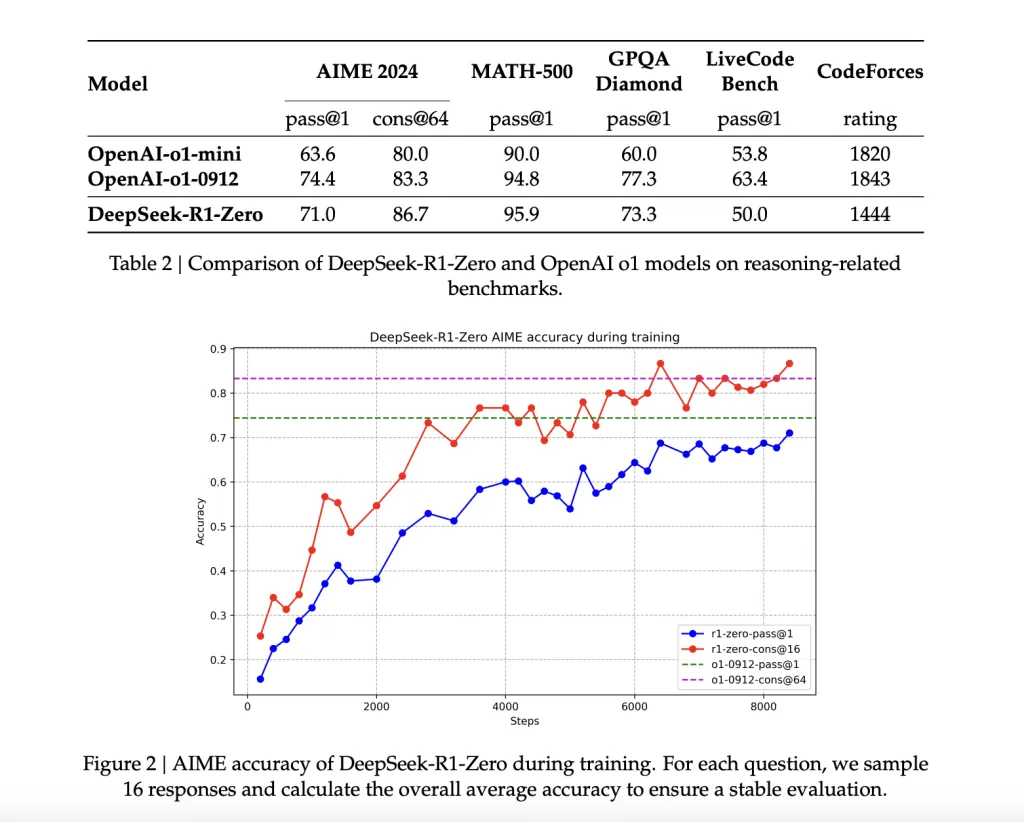
This model relies on RL without using supervised data. Leveraging Group Relative Policy Optimization (GRPO), it optimizes reasoning by evaluating multiple outputs, leading to significant improvements in benchmark performance. For example, its AIME 2024 pass@1 score increased from 15.6% to 71.0% during training.
Multi-Stage Training in DeepSeek-R1
DeepSeek-R1 integrates cold-start data—thousands of carefully curated CoT examples—for pre-fine-tuning the base model before conducting reasoning-focused RL. This process ensures that outputs are both coherent and user-friendly by incorporating language consistency rewards.
Model Distillation for Efficiency
To address computational constraints, DeepSeek-AI distilled six smaller models (ranging from 1.5B to 70B parameters) from DeepSeek-R1 using Qwen and Llama architectures. These distilled models maintain strong reasoning capabilities. For instance, the 14B distilled model achieved a 69.7% pass@1 score on AIME 2024, outperforming some larger models.
Performance Highlights
Reasoning Benchmarks
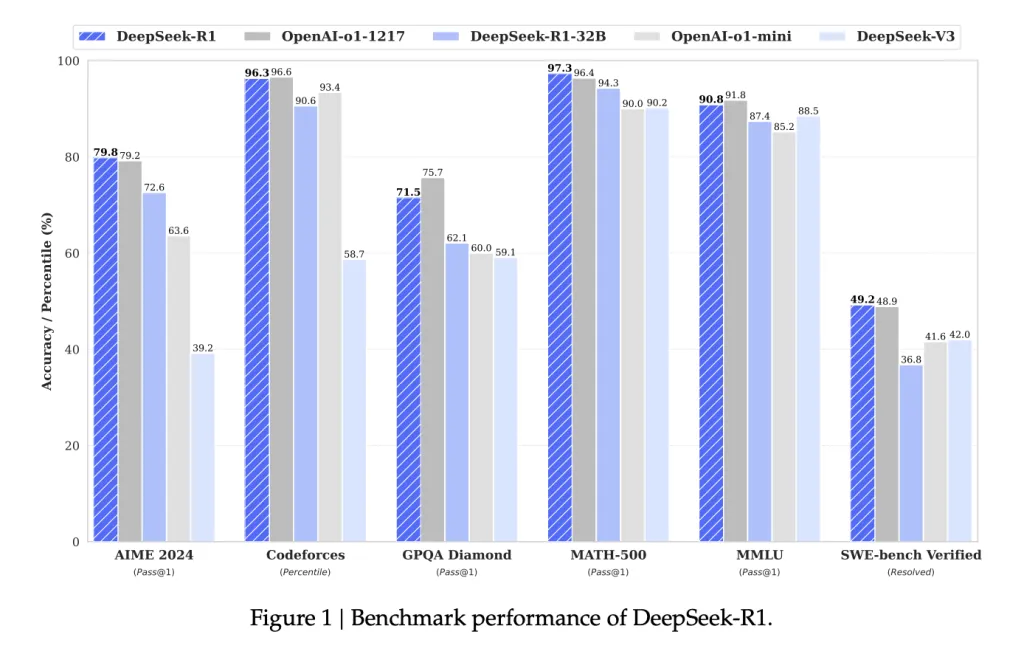
- AIME 2024: 79.8% pass@1, outperforming OpenAI's o1-mini.
- MATH-500: 97.3% pass@1, on par with OpenAI-o1-1217.
- GPQA Diamond: 71.5% pass@1, excelling in fact-based reasoning.
Coding and STEM Tasks
- Codeforces Elo Rating: 2029, surpassing 96.3% of human participants.
- SWE-Bench Verified: 49.2% resolution rate, competitive with other leading models.
General Capabilities
- Demonstrated strong generalization on ArenaHard and AlpacaEval 2.0 benchmarks, achieving 92.3% and 87.6% win rates, respectively.
Distilled Model Highlights
- Smaller models, such as DeepSeek-R1-Distill-Qwen-32B, showcased excellent performance, with a 72.6% pass@1 score on AIME 2024, demonstrating effective scalability and practicality.
A Significant Step in LLM Reasoning
DeepSeek-AI’s DeepSeek-R1 and DeepSeek-R1-Zero represent a significant advancement in enhancing the reasoning capabilities of LLMs. By utilizing RL, cold-start data, and distillation techniques, these models address critical limitations while promoting accessibility through open-source availability under the MIT license.
The API (model=deepseek-reasoner) further enhances usability for developers and researchers. Looking ahead, DeepSeek-AI aims to:
- Improve multilingual support,
- Enhance software engineering capabilities, and
- Increase prompt sensitivity.
These efforts aim to establish DeepSeek-R1 as a powerful solution for reasoning-focused AI applications.
By adopting thoughtful training paradigms, DeepSeek-R1 demonstrates how AI can evolve to tackle increasingly complex challenges.
Try it now: deepseek-r1